공식 문서 : http://spark.apache.org/docs/latest/index.html
Apache Spark는 빠르고 일반적인 범용 클러스터 컴퓨팅 시스템입니다.
Java, Scala, Python 및 R의 고급 API와 일반 실행 그래프를 지원하는 최적화 된 엔진을 제공합니다. 또한 SQL 및 구조화 된 데이터 처리를위한 Spark SQL, 기계 학습을위한 MLlib, 그래프 처리를위한 GraphX 및 Spark Streaming을 비롯한 다양한 고급 도구 세트를 지원합니다.
아래 그림에서 자세히 알아봅니다.
특징
- 인메모리
- 단일 시스템에서 배치/스트림 처리, SQL, ML Graph 프로세싱 지원
- 자바 스칼라 파이션 등 인터페이스 제공
- Strandalone 은 물론 YARN, mesos 등의 클러스터 리소스 관리 패키지를 통해 다양한 환경에서 구동가능
- 8000 개 이상의 노드 추가 가능 확장성 확보
- HDFS, 카산드라, 흐브, S3 등 다양한 데이터의 활용 가능
Spark SQL - SQL / HiveQL 같은 쿼리 작업이 가능하게 해주는 라이브러리
RDD - 본 문서에서 다룸
DataFrame / DataSet - 테이블과 비슷한 형태로 Rows objects 들의 집합
- DataFrame/DataSet 은 다양한 input source 를 지원
- 존재하던 RDD
- JSON
- HiveQL
- ODBC / JCBC 서버 연동

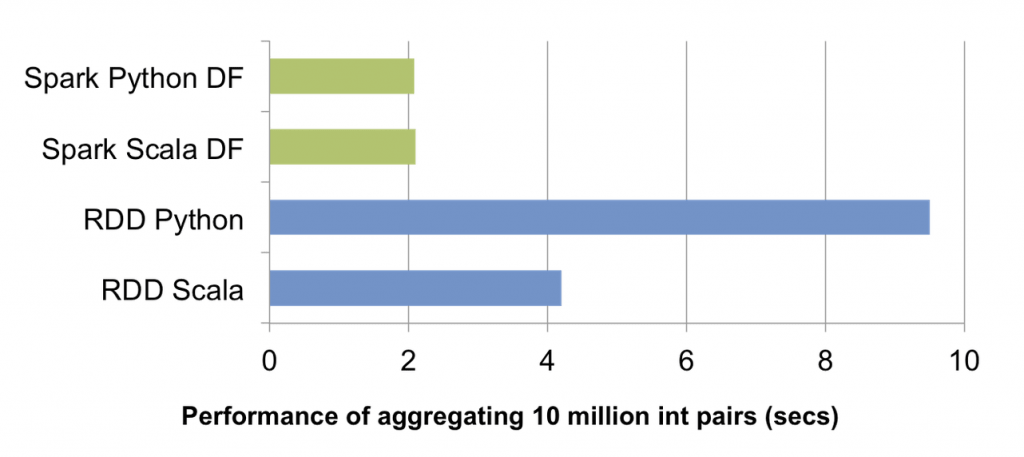
RDD, DataFrame 뭐가 좋나?
https://databricks.com/blog/2016/01/04/introducing-apache-spark-datasets.html
Spark RDDs vs DataFrames vs SparkSQL
https://community.hortonworks.com/articles/42027/rdd-vs-dataframe-vs-sparksql.html
이 내용은 별도 페이지로 정리하도록 한다.
http://dadk.tistory.com/74
Spark 구성요소

아파치 스파크 코어
스파크 코어 다른 모든 기능이에 구축 스파크 플랫폼의 기본 일반 실행 엔진입니다. 이는 인 메모리 컴퓨팅 및 외부 스토리지 시스템에서 참조하는 데이터 세트를 제공합니다.
스파크 SQL
스파크 SQL 구조화 및 반 구조화 된 데이터에 대한 지원을 제공 SchemaRDD라는 새로운 데이터 추상화를 소개 스파크 코어의 상단에 구성 요소입니다.
스파크 스트리밍
스파크 스트리밍 스트리밍 분석을 수행하는 코어의 빠른 스케줄링 기능을 스파크 활용합니다. 이 미니 일괄 적으로 데이터를 섭취 및 데이터의 그 미니 배치에 RDD (탄력 분산 데이터 집합) 변환을 수행한다.
MLlib (기계 학습 라이브러리)
MLlib는 스파크 위 때문에 분산 메모리 기반 스파크 아키텍처의 분산 기계 학습 프레임 워크입니다. 그것은, 벤치 마크에 따르면, 교류 최소 제곱 (ALS) 구현에 대한 MLlib 개발자에 의해 수행된다. 스파크 MLlib은 (두싯는 스파크 인터페이스를 얻은 전) 구 배 빨리 아파치 머하 웃의 하둡 디스크 기반 버전입니다.
GraphX
GraphX??는 스파크의 상단에 분산 그래프 처리 프레임 워크입니다. 이 프레 겔 추상화 API를 사용하여 사용자 정의 그래프를 모델링 할 수 그래프 연산을 표현하기위한 API를 제공한다. 또한이 추상화에 최적화 된 런타임을 제공합니다.
Spark Application 개발은 아래의 3가지에 대한 이해를 바탕으로 시작
1. RDD
2. RDD 변환 API (Scala / Python / java / R interface)
3. RDD 변환 API 로 만들어진 SQL / ML / graph / stream Library (Scala / python.. 상동)
1 성능
저장방식 : 메모리 Read-only
성능이 좋다. 기존 Hadoop, HadoopBM 과 비교해도 빠르다.
머신이 늘어나도 성능이 유지된다
기존에는
HDFS + MapReduce 하둡, SQL 질의를 위한 Hive, Oozie, 하둡->대량데이터 전송을 위한 Sqoop 등을 써야 했다.
하둡 API 자체도 어려웠고 접근이 더 어려움.
2 RDD (Resilient Distributed Datasets)
핵심 : RAM 으로 적재하면서 Read-only 로 처리
- 막말로 Spark 는 RDD + Interface 라 할 수 있다.
- 두가지 논문이 근간을 이룸
GFS
스탠포드 = 정석
사골 (읽어볼 수록 새로움)
RDD
버클리 = 개념원리
라면 (후루룩 읽힘)
- 배열 다루듯이 하면 된다. RDD 를 다룬다는건 컬렉션을 다룬다는 뜻.
- RDD 를 데이터를 생성하는 두가지 방법
* Parallelized
sc.parallelize(Array(1,2,3,4,5))
* External Datasets
sc.textFile("data.txt")
2-1 RDD 에 대해서 좀더 알아보자
RDD는 병렬로 작동 할 수있는 클러스터 노드간에 분할 된 요소 모음입니다.
RDD는 Hadoop 파일 시스템 (또는 다른 Hadoop 지원 파일 시스템)이나 드라이버 프로그램의 기존 Scala 컬렉션에서 시작하여 파일을 변환하여 만들어집니다.
사용자는 Spark에 메모리에 RDD를 유지하도록 요청하여 병렬 작업에서 효율적으로 재사용 할 수 있습니다.
마지막으로, RDD는 노드 장애로부터 자동으로 복구됩니다.
다음문서에서 Spark Shell 기반으로 RDD 핸들링 하는 방법과 관련 사항을 알아보도록 하겠다.
http://dadk.tistory.com/67
2-2 Dataset / DataFrames
RDD 보다 Dataset (dataframes) 이 더 빠르다
https://databricks.com/blog/2016/01/04/introducing-apache-spark-datasets.html
(RDD 와 Dataset 은 별도 포스팅으로 알아보도록 한다.)
3. DStream (Discretized Streams)
시간 흐름에 따른 순차적 데이터를 의미 내부적으로 DStream 은 각 시점에 RDD 스퀸스이다.
Flume, Kafka 또는 HDFS 와 같은 많은 input 유형으로 부터 생성될 수 있다.
Dtream 두가지 Operation
Transformation
DStream 을 생성(파생)
operation 은 두가지로 구분 할 수 있다.
Stateless
이전 Batch 결과 데이터에 영향을 받지 않는 데이터를 처리
map(), filter(), reduceByKey() 같은 Operation 들
Stateful
이전 Batch 결과 데이터를 현재 Batch 결과를 만들기 위해 사용
Sliding Window 나 기간내 상태 주적 등이 있다.
Output
외부 데이터 저장소에 결과 저장
4 RDD 두가지 액션
- transformations
데이터를 개발자가 원하는 모양으로 변형시키는 것
(map, reduce, join) 데이터의 이합집산, 지지고 볶는 흐름 단순히 map, reduce 만 있던 MR 보다 명령어 풍부
Trasfomation 의 결과는 항상 RDD 이다.
- Action
모든 trasformations 결과를 내 높아라
trans->trans->....trans->action
액션을 실행하는 순간 데이터 변형(Transfomation)을 얻음(?) 결과는 value
Action 을 실행해야 Job 이 나온다.
Operation 의 순서를 기록해 DAG 로 표현한 것을 Lineage 라 부른다.
하나의 RDD 는 여러개의 파티션으로 나뉜다.
5. Spark Streaming
실시간 데이터 스트림의 확장 성, 높은 처리량, 내결함성 스트림 처리를 가능하게하는 핵심 Spark API의 확장입니다.
http://spark.apache.org/docs/latest/streaming-programming-guide.html
Kafka, Flume, Kinesis 또는 TCP 소켓과 같은 많은 소스에서 데이터를 수집 할 수 있으며 map, reduce, join 및 window와 같은 고급 함수로 표현 된 복잡한 알고리즘을 사용하여 데이터를 처리 할 수 있습니다. 마지막으로 처리 된 데이터를 파일 시스템, 데이터베이스 및 라이브 대시 보드로 푸시 할 수 있습니다. 실제로 Spark의 기계 학습 및 그래프 처리 알고리즘을 데이터 스트림에 적용 할 수 있습니다.
6. Spark Application 처리 구조

Driver Program - main() 함수를 가지고 있는 프로세스 (SparkContext 객체를 생성하고 RDD 를 전달)
Application을 task 라고 불리는 실제 수행 단위로 변환을 task를 묶어서 Worker Node의 Excutor 로 전달
Worker Node - 실제 작업을 수행하는 노드
Cluster Manager - 클러스터에서 필요한 자원을 찾아줌
Excutor
- Task 를 수행하는 프로세스 Executor 가 오류가 나면 대체 Executor 에게 Job 할당 (멀티 스레드에서 tasks 를 수행하고 결과를 Driver Program 에게 전송)
- Cache 하는 RDD 를 저장하기 위한 메모리 공간 제공
Task - 익스큐터에 할당되는 작업의 단위
Job - 사용자 입장에서의 작업의 단위 (Task 의 조합)
7. Spark Application 실행동작 순서 흐름
1 사용자 Spark-submit 을 사용해 작성 어플 실행
2 Submit 은 Driver Program 을 실행하여 main() 호출
3 Driver 에서 생성된 SparkContext 는 Cluster Manager 로 부터 Executor 실행을 위한 리소스 요청
4 Cluster Manager 는 Excutor 를 실행
5 Driver Program 은 Application을 Task 단위로 나누어 Excutor 에게 전송
6 Executor 는 Task 를 실행
7 Executor 는 Application 이 종료되면 결과를 Driver Program 에게 전달하고 클러스터 매니저에게 리소스 반납.
참조할만한 문서
Spark SQL for SQL
Hadoop의 Hive가 아닌 Spark SQL을 통해 SQL을 MapReduce없이 빠르게 처리가 가능합니다.
http://spark.apache.org/docs/latest/sql-programming-guide.html
Structed data processing
Json, Parquet 등의 다양한 struced data processing을 지원합니다.
MLlib for machine learning
Classification, Regression, Abnormal Detection, Clustering 등의 다양한 machine learning algorithm을 제공합니다.
http://spark.apache.org/docs/latest/ml-guide.html
GraphX for graph processing
graph processing을 지원하는 GraphX를 제공합니다.
http://spark.apache.org/docs/latest/graphx-programming-guide.html
Spark Streaming.
streaming처리가 가능한 storm처럼 spark에서도 batch processing 외에도 streaming처리가 가능합니다.
http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
http://spark.apache.org/docs/latest/streaming-programming-guide.html
Launching on a Cluster
Sparks를 클러스터에서 동작하게 하기 위해서는 cluster manager가 필요합니다.
Cluster Manager 종류
Amazon EC2
Standalone Deploy Mode
Apache Mesos
Hadoop Yarn
Download
스파크는 binary, build 버전을 받을 수 있습니다. [다운로드] 만약 binary를 다운로드 받으신다면, Hadoop버전에 맞는 package type을 선택하셔야 합니다. 저 같은 경우에는 hadoop2.6의 hdfs와 yarn위에서 동작시키기 위해 Hadoop 2.6 prebuilt된 버전을 다운로드 했습니다.
wget http://d3kbcqa49mib13.cloudfront.net/spark-1.6.1-bin-hadoop2.6.tgz
그외
1. Spark 실행
스파크는 Windows, UNIX (e.g. Linux, Mac OS)에서 동작이 가능합니다. Spark를 사용하기 위해서는 사전 설치해야하는 항목들이 있습니다. Spark는 JVM위에서 동작하기 때문에 JAVA는 필수입니다. Java 7+, Python 2.6+, R 3.1+, Scala를 사용하기 위해서는 2.10을 설치해야 합니다.
2 Running the Examples and Shell
Spark를 다운로드 받으면 $SPARK_HOME/examples/src/main의 경로에 언어별로 간단한 예제를 제공하고 있습니다.
3 Interactive Shell 지원
$SPARK_HOME/bin/pyspark --master local[2]
python interative shell도 제공을 합니다.
$SPARK_HOME/bin/spark-submit examples/src/main/python/pi.py 10
실행 결과는 Pi is roughly 3.140176
당연히 Scala 도 가능
$SPARK_HOME/bin/run-example SparkPi 10
interactive scala shell을 실행할 수 있습니다.
3-1 master local[2] 옵션
$SPARK_HOME/bin/spark-shell --master local[2]
--master local[2] 옵션은 spark를 2개의 worker threads로 locally 실행한다의 의미 입니다. (--help로 확인 가능)더 자세한 내용은 아래 참고하세요.
https://spark.apache.org/docs/latest/submitting-applications.html#master-urls
4. R 언어지원
Spark 1.4부터 R을 제공합니다.
$SPARK_HOME/bin/sparkR --master local[2]
$SPARK_HOME/bin/spark-submit examples/src/main/r/dataframe.R
참조문서
https://spark.apache.org/docs/1.6.2/streaming-programming-guide.html